서비스 배포를 하기 전 어느정도 사용자가 이 서버를 버틸 수 있을까 점검할 필요가 있어서 서버 과부화 테스트를 진행했다.
서버 과부화 테스트를 하기 위해 나는 ngrinder를 사용했다.
서버는 ec2 프리티어를 사용했고 실제 서비스를 운영할 때는 프리티어를 절대 사용 안 할 것이지만 지금은 배포 전 단계니까 프리티어를 최대한 사용하자는 마인드로 프리티어를 선택했다..
ngrinder 사용하는 법은 구글링을 하면 많이 찾을 수 있어서 다른 글 참고하길 바란다..

나는 우선 헤더 설정같은 기본적인 스크립트 작성을 안 하고 퀵 스타트로 빠르게 진행을 해보았다.
url에는 https://example.com/api/~~~~ 이런식으로 입력하고 테스트를 진행하면 된다.


에이전트는 1개 사용자는 296명 테스트 시간은 1분으로 설정을 했다
결과는..
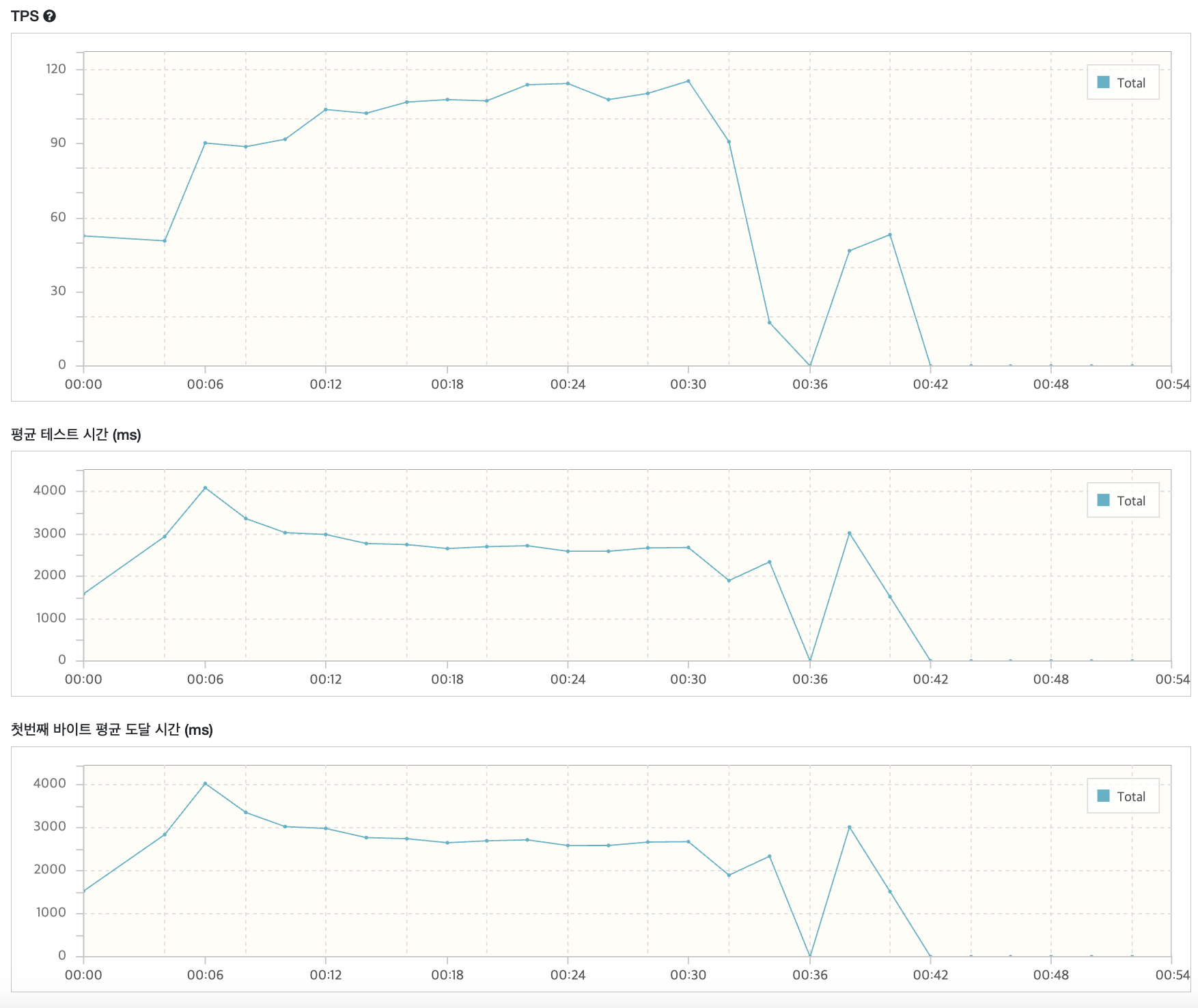
요약을 하자면 30초 이후부터 TPS가 급격히 떨어지고 응답 시간이 0으로 수렴해 서비스 장애가 발생한 것으로 보인다..
쉽게 말하면 서버가 터진 느낌이다..!
TPS는 시스템이 1초에 몇 건의 요청(트랜잭션)을 실제로 처리했는지를 보여준다
일반적으로 TPS가 높을수록 처리 성능이 우수함을 의미한다..
첫번째 바이트 평균 도달 시간은 사용자가 서버에 보내고, 서버가 응답 데이터의 "첫번째 바이트"를 보내기까지 걸린 평균 시간이다.
네트워크 지연, 백엔드 연산, DB 질의 등 모든 구간의 초기 응답 지연을 포함한다.
TTFB(첫번째 바이트 평균 도달 시간)가 짧을수록 사용자는 더 빠르게 응답을 느낀다. 서버 처리 지연이나 네트워크 병목을 의심할 수 있는 지표다.
나의 TPS는 초반에는 60~120 TPS로 비교적 높게 유지되어, 초기 부하까지는 서버가 정상적으로 트래픽을 처리하고 있다
약 30초 경과 후 TPS가 급격히 하락해, 이후 거의 0에 가까워집니다. 이는 서버 장애, 리소스 한계 도달 혹은 심각한 성능 병목이 발생했음을 의미한다
TTFB는 초반에는 TTFB가 2000~4000ms(2~4초)로 매우 높게 형성되어 있다. 이는 서버 내 연산, 데이터베이스 접근, 네트워크 병목 중 하나 이상의 영역이 병목임을 시사한다..
30초 이후부터는 TPS 변화와 마찬가지로 TTFB 측정값도 사라지며, 트랜잭션 자체가 처리되지 않는 장애 패턴이 나타난다.
그래프 결과만 보고 프리티어 환경의 한계 때문인지, 코드/구조상의 성능 문제인지 단정하기는 어려워서 서버 환경, 코드 구조상의 문제를 모두 리펙토링을 할 예정이다.
프리티어 환경 한계 가능성은 30초 이후 서버가 “터진 듯” TPS가 급락하는 현상은 흔히, 리소스 임계치 도달(스레드, 커넥션, 메모리, DB 커넥션 제한 등)에서 발생하는 이유가 있을 것 같다.
코드/구조 문제 가능성은 부하 초기에 TTFB(첫 바이트 시간)가 이미 2~4초대로 굉장히 높다는 점은, 서비스/코드의 내부 연산이나 DB 쿼리, 외부 API 호출 등 자체 병목이 존재할 가능성이 높다는 신호다. 최적화된 코드라면 저사양 환경이라도 어느 정도의 응답성은 기대할 수 있지만, 비효율적 쿼리, N+1 문제, 대량 동시 요청 시 컨테이너 풀 고갈 등이 있으면 상황이 극단적으로 악화된다..
내 생각에 코드를 객체지향적, N+1 문제도 해결한 코드를 작성한 줄 알았는데 아닌가보다. 더 리펙토링을 진행해서 성능 문제를 해결하겠다.
'IT > Cloud' 카테고리의 다른 글
| Spring Boot 서버를 AWS ECS Fargate로 배포하기 - Route 53 + ACM으로 HTTPS 적용 (3) (0) | 2026.03.28 |
|---|---|
| Spring Boot 서버를 AWS ECS Fargate로 배포하기 - ALB로 고정 도메인 연결 (2) (0) | 2026.03.28 |
| Spring Boot 서버를 AWS ECS Fargate로 배포하기 - ECR + ECS + GitHub Actions CI/CD 구축 (1) (0) | 2026.03.26 |
| Nginx Rate Limiting으로 DDoS 공격 막기 (0) | 2026.02.14 |
| 스프링부트 서버 과부화 테스트(2) (0) | 2025.09.10 |


